Choosing an AI Model for Support Agents: GPT-5 & GPT-5.4 Get Cheaper


Choosing an AI model for support agents is mostly a trade-off between three things — capability, speed, and cost — and on June 17, 2026 we made that trade-off easier by cutting the price of two of the most capable models in Macha: GPT-5 dropped from 3 credits to 2, and GPT-5.4 dropped from 5 credits to 3, per response. Nothing about your plan changed, nothing about the models changed — the same agents you're already running now cost less every time they reply. If you were rationing GPT-5.4 to a handful of high-stakes agents because it was expensive, that calculus just shifted.

This post is the practical, decision-oriented version: what actually changed, the new per-model math on a real 10,000 credits allowance, how the OpenAI models stack up against the Claude Sonnet and Groq options Macha also offers, and — the part most teams care about — how to choose which model each of your support agents should run on now that the gap between "cheap" and "capable" narrowed.
A note on what a credit is, because it matters here: in Macha a credit is spent per AI action — one complete assistant response from an agent — not per resolved ticket or per "deflection." A model's credit cost is just how much one of its responses costs. So when we say GPT-5 went from 3 to 2, every reply that agent writes got a third cheaper.
What changed on June 17
The whole lineup, with the change highlighted:
| Model | Credits / response | Change | Where it fits |
|---|---|---|---|
| GPT-5.4 Mini | 1 | unchanged (the default) | Fast, high-volume. Most workflows. |
| GPT-5 | 2 | ↓ from 3 | The balanced middle. Nuanced replies at volume. |
| GPT-5.4 | 3 | ↓ from 5 | Highest OpenAI capability. Strict, complex agents. |
GPT-5.4 Mini stayed put at 1 credit and remains the default for new agents — it was already the value pick, and we left it alone. The cuts land on the two models above it, which is where the price was actually doing the rationing.
For context on the trajectory: GPT-5.4 only launched in Macha on April 23 at 5 credits as OpenAI's most capable model (1M-token context window), with GPT-5 as the 3-credit default. Two months of running it in production told us the value was there at a lower price. GPT-5.4 Mini, meanwhile, had already been cut from 1.25 to 1 credit back in April when it became the default — so the only model that hasn't moved in months is the one most of you are already on.
The broader Macha model lineup spans roughly 0.5 to 9 credits per response depending on the model — including Anthropic's Claude Sonnet 4.5 and 4, and faster Groq-hosted options — so the three OpenAI models here sit in the affordable-to-mid band of what's available. The exact per-model cost is always shown next to the picker before you commit to a model.
What the cut actually buys you
Lower credit costs don't change your monthly allowance — they change how far it stretches. On the Professional plan's 10,000 credits per month, here's the honest before/after, assuming an agent does nothing but reply:
| Model | Responses before | Responses after | Change |
|---|---|---|---|
| GPT-5 (3 → 2 credits) | ~3,333 | ~5,000 | +50% |
| GPT-5.4 (5 → 3 credits) | ~2,000 | ~3,333 | +67% |
So a GPT-5 agent now gets you half again as many responses on the same plan, and a GPT-5.4 agent gets you two-thirds more. (Real agents also spend credits on tool calls and sub-agent delegation, so treat these as ceilings for the reply portion, not a literal monthly quota.) The point isn't the exact number — it's that the more capable models are now meaningfully cheaper to run at volume, which is what unlocks using them where you previously couldn't justify it.
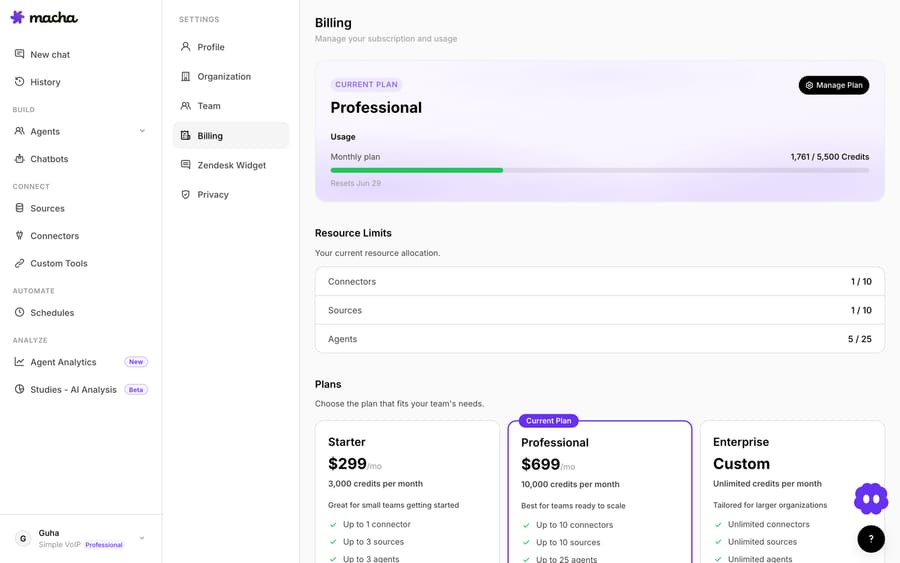
If you do run low, monthly credits aren't the only lever — top-up packs add credits that persist across billing cycles and are spent automatically after your monthly allowance. But for most teams the cut alone means the same plan now covers more ground. See the pricing page for current plans and credit allowances.
How to actually pick a model for a support agent
This is the question the price cut reopens, so let's answer it properly. The industry framing — borne out across model-selection guides from Microsoft's Foundry team and support-focused write-ups like Cobbai's LLM evaluation guide — is that you're trading off three things: capability, latency, and cost. There's no single best model; there's a best model for a given agent's job. Here's how we'd map Macha's three OpenAI options.
Default to GPT-5.4 Mini for the bulk of your volume
For most support work — answering "where's my order," explaining a policy, looking up an account, triaging and routing — GPT-5.4 Mini at 1 credit is the right call, and it's the default for a reason. It's fast, it's cheap enough to run on your busiest agents without thinking about it, and with a 400K-token context window it can hold long ticket histories and knowledge-base context without truncating. The consensus across support-automation research is that mini-class models are the best value for high-volume, latency-sensitive support — and that matches what we see. We wrote a deeper piece on exactly this: GPT-5.4 Mini for customer support.
Step up to GPT-5 when replies need more nuance
GPT-5 (now 2 credits) is the balanced middle: better at nuanced, judgment-heavy replies than Mini, while still cheap enough to run at scale. Good candidates are agents that draft customer-facing prose where tone and reasoning matter — apology-and-remedy responses, technical explanations, anything where a slightly flat or literal answer would read poorly. With the cut, the premium over Mini is now just one credit per reply, which is easy to justify on a customer-facing agent.
Reserve GPT-5.4 for strict, complex, high-stakes agents
GPT-5.4 (now 3 credits) is the highest-capability OpenAI model in the platform, and its real edge over GPT-5 is instruction-following — agents with strict "do this exactly once" rules, complex branching logic, or many tools where the model has to reliably pick the right one in the right order. If you've ever watched a cheaper model skip a step or call a tool twice, that's the failure mode GPT-5.4 is built to avoid. It's the model for billing/refund flows, multi-tool runbooks, and orchestration agents that delegate to sub-agents — the places where a wrong action is expensive. At 3 credits it's now the same cost the default GPT-5 was two months ago.
A common pattern that the lower prices make easier is tiering: a Mini-powered front-line agent handles the routine majority and delegates the gnarly cases to a GPT-5.4 specialist sub-agent. You pay the premium only on the small slice of conversations that need it. Because Macha lets each agent — and each sub-agent — set its own model, you can build that tier directly. The agents documentation covers per-agent model selection and delegation.
OpenAI isn't the only option: Claude Sonnet and Groq
If you've read any of the cross-provider model round-ups — the LLM API pricing comparisons that stack OpenAI against Claude, Gemini, and Llama — you'll know "choosing a model" is rarely an OpenAI-only decision. It isn't in Macha either. The three OpenAI models above are the most-used defaults, but the picker also includes Anthropic's Claude Sonnet (4.5 and 4) and Groq-hosted open models, and they earn their place for different jobs:
| Provider / model | Best at | Why reach for it |
|---|---|---|
| OpenAI GPT-5.4 Mini (1 credit) | Speed + broad capability | The default; best all-round value for high-volume support, strong tool ecosystem |
| OpenAI GPT-5 / GPT-5.4 (2 / 3 credits) | Nuance + strict instruction-following | Customer-facing prose and complex, multi-tool runbooks |
| Anthropic Claude Sonnet (4.5 / 4) | Tone, empathy, long-document reasoning | Sensitive replies and agents that reason over long policies or 100-page manuals |
| Groq open models | Raw latency + low cost | Ultra-fast, cheap responses for simple, high-frequency lookups |
The industry pattern, borne out in support-LLM guides, is that mini-class OpenAI models win on all-round value, Claude leads on instruction adherence and long-context reasoning, and the cheapest/fastest providers (Groq, and outside Macha, Gemini Flash or Llama) win when latency and per-message cost dominate. So if an agent's job is empathetic, sensitive handling — refund apologies, complaints, anything where tone carries the resolution — it's worth A/B testing Claude Sonnet against GPT-5 on a few real tickets before you commit. And if you have a high-frequency, dead-simple lookup agent, a Groq model can undercut even GPT-5.4 Mini on both speed and credits. The point of the price cut isn't "always pick OpenAI" — it's that you can match each agent to the provider that fits its job, and the costs are now close enough that capability, not budget, drives the choice.
A note on where the model is set
Worth flagging, because June 17 also tightened this: the model dropdown in the top-right of a conversation only changes the model for that one chat. It's there for quick experiments — try a reply on GPT-5.4, compare it to Mini, decide. If you want an agent to permanently run on a different model, that lives in the agent's configuration (and the org-wide default lives in Settings). The dropdown now shows a toast saying as much, so you don't accidentally think a one-off switch stuck. It's a small thing that prevents a real "why is my agent still on the old model" confusion.
Watch-outs and when not to reach for the expensive model
Cheaper top-tier models are not a reason to put every agent on GPT-5.4. A few honest caveats:
- More capable ≠ always better for support. For fast, friendly, high-volume chat, a lighter model is often the better customer experience because it's quicker — capability you don't need just adds latency. Don't upgrade an agent that's already answering correctly.
- The cheapest mistake is still a mistake. The credit cost is the small number; a wrong refund or a mis-routed escalation is the big one. Match the model to the cost of being wrong, not just the cost per response.
- Vision and tooling vary by model. Image-reading on Zendesk attachments works on GPT-5.4 Mini and Claude Sonnet models; if an agent needs to read receipts or screenshots, check the model supports it before switching.
- These are Macha credit costs, not OpenAI list prices. A credit is Macha's unit for one AI action across all providers; the underlying token economics differ by model. Don't reverse-engineer your OpenAI bill from credit counts.
- Test before you roll out. Use the per-conversation dropdown to compare a real ticket on two models before you change an agent's default. It's free to look.
The healthiest setup for most teams is still Mini almost everywhere, GPT-5 on the customer-facing agents that write a lot of prose, GPT-5.4 reserved for the strict/complex few — and the June 17 cut just made the second and third tiers cheaper to adopt.
FAQ
What exactly changed on June 17, 2026? GPT-5 went from 3 credits per response to 2, and GPT-5.4 went from 5 credits to 3. GPT-5.4 Mini stayed at 1 credit and remains the default. No plan, allowance, or model behavior changed — only the per-response cost.
Do I have to do anything to get the lower price? No. Existing agents on GPT-5 or GPT-5.4 simply cost less per response from June 17 onward. There's nothing to migrate.
Is a credit the same as a resolved ticket? No. A credit is spent per AI action — one complete assistant response. A single ticket might take several responses (and tool calls), and Macha is automation/orchestration, so outcomes vary. Credits measure work done, not tickets closed.
Which model should most of my agents use? GPT-5.4 Mini (1 credit) for the high-volume majority, GPT-5 (2 credits) for nuanced customer-facing replies, and GPT-5.4 (3 credits) for strict, complex, or high-stakes agents. See the GPT-5.4 Mini deep dive for the default case.
Is OpenAI the only provider, or can I use Claude? Macha isn't OpenAI-only. The model picker also includes Anthropic's Claude Sonnet (4.5 and 4) — strong on tone, empathy, and long-document reasoning — and Groq-hosted open models for ultra-fast, low-cost responses. For sensitive, tone-sensitive replies it's worth testing Claude Sonnet against GPT-5 on real tickets; for dead-simple high-frequency lookups, a Groq model can be the cheapest and fastest option.
How do I change an agent's model permanently? In the agent's configuration card, not the conversation dropdown (which only affects the current chat). The org-wide default lives in Settings. The docs walk through it.
Try it
Macha runs your AI agents on top of the helpdesk you already use — Zendesk, Freshdesk, Gorgias, or Front — and lets you pick the right model for each agent's job. If you've been holding a smart agent back on cost, now's the time to revisit it. Start a 7-day free trial, no credit card required, or read more about running Macha on Zendesk.
Written by Abbas (Customer Support & AI, Macha) · Reviewed by Ankeet Guha (Co-founder & CTO) · Published 2026-06-24 · Last updated 2026-06-24.















