



 Shopify
Shopify Stripe
Stripe Slack
Slack Notion
Notion Google Workspace
Google Workspace Confluence
ConfluenceHow to Connect Your Knowledge Base to an AI Agent (2026)


An AI agent is only as good as what it knows. Connect it to your real knowledge — your help center, docs, and wiki — and it answers accurately, with your specifics. Skip that step, and it guesses. This guide explains why grounding matters, which knowledge sources you can connect, how to do it, and how to keep your agent's answers trustworthy.

Why grounding an agent in your knowledge matters
A raw language model knows a lot about the world and nothing about your product, policies, or edge cases. Point an agent at your knowledge base and three things change:
- Accuracy — it answers from your documented truth, not a plausible guess.
- Fewer hallucinations — when the answer is in your content, it cites it; when it isn't, a well-built agent escalates instead of inventing.
- Always current — update an article and the agent's answers update with it.
This is the difference between a chatbot that sounds confident and one that's actually right.
How it works (in plain terms)
When you connect a knowledge source, the platform indexes it: each document is split into chunks, turned into embeddings (a searchable mathematical representation), and stored for fast retrieval. When a customer asks something, the agent runs a hybrid search — combining meaning-based (semantic) and keyword matching — to find the most relevant passages, then answers from them. It can also pull a full document on demand when it needs the detail.
You don't have to manage any of that plumbing — you just connect the source and link it to an agent.
What knowledge sources you can connect
With a platform like Macha, an agent can draw on a mix of sources:
- Zendesk Help Center — articles auto-sync. Publish a new one and the agent knows it; unpublish one and it stops citing it.
- Notion — connect live pages.
- Confluence — connecting it auto-creates a knowledge source from your spaces.
- Google Docs — link live documents.
- Uploaded files — PDFs, DOCX, TXT, CSV, XLSX (up to 20 MB each).
- Your website — crawl a site (up to 200 pages) or index a single page.
- Past tickets — results from bulk analysis (Studies) can be pushed in as a searchable source.
The point is one agent can blend your public help center and your internal docs — not just one silo.
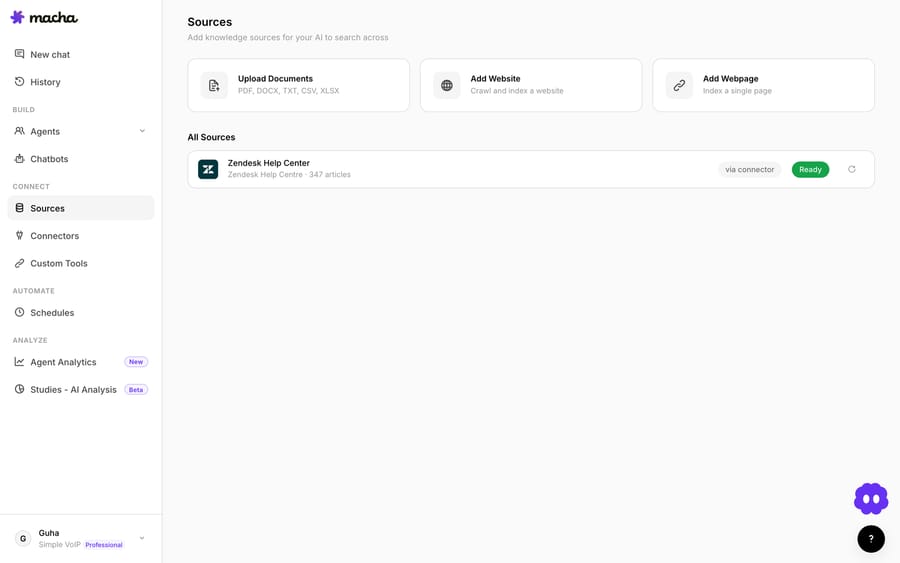
How to connect your knowledge base (step by step)
- Connect the source. For Zendesk, connecting the Help Center sets up auto-sync. For Notion, Confluence, or Google, authorize the connection and pick what to include. For files, upload them; for a site, paste the URL to crawl.
- Let it index. The platform chunks and embeds the content automatically — no setup on your end.
- Link the source to your agent. Scope it: give the agent all docs in a source or only selected ones, so each agent sees exactly the knowledge it should.
- Test it. Ask the agent questions you know the answers to, and check it cites the right content.
- Keep it fresh. Your Help Center stays in sync automatically; resync other sources when they change.
A nice detail on cost: indexing your knowledge doesn't consume credits — embedding and storage aren't billed. Your agent only spends credits when it actually responds (and even then, 0.5–9 credits per action depending on the model). So connecting a big knowledge base is free; you only pay for the work the agent does. Plans start at $299/mo. 7-day free trial, no credit card required.
What to connect first (and in what order)
You don't need to connect everything on day one. A pragmatic order:
- Your Help Center — the auto-sync makes it zero-maintenance, and it already covers your most common questions.
- Your top 20 articles by ticket volume — if they aren't in the Help Center yet, add them; this is where most resolutions come from.
- Policies (refunds, shipping, billing) — the rules the agent needs to answer correctly and consistently.
- Internal docs (Notion/Confluence) for the questions your public content doesn't cover.
Then watch what the agent gets asked that it can't answer, and fill those gaps. Your knowledge base improves alongside your automation — the questions customers actually ask tell you exactly what to write next.
Best practices
- Curate, don't dump. Connect your good content. Garbage in, confident-wrong out.
- Keep it current. Retire stale articles; the agent will faithfully repeat whatever you leave in.
- Have a single source of truth. Avoid three conflicting versions of the same policy.
- Scope per agent. A refund agent doesn't need your engineering wiki. Give each agent only what's relevant.
- Write for retrieval. Clear titles and focused articles get found and cited more reliably.
Common pitfalls
- Thin or outdated knowledge → vague or wrong answers. Fix the content first.
- No escalation path → the agent guesses when it shouldn't. Make sure it hands off when unsure.
- Over-broad sourcing → the agent surfaces irrelevant docs. Scope tightly.
Frequently asked questions
How does an AI agent use my knowledge base? It indexes your content, then searches it (semantic + keyword) to answer each question from the most relevant passages — and can pull a full document when it needs detail.
What knowledge sources can I connect? Your Zendesk Help Center (auto-synced), Notion, Confluence, Google Docs, uploaded files (PDF/DOCX/CSV, etc.), a crawled website, and even past-ticket analysis.
Does the agent stay up to date when I change an article? Yes — the Zendesk Help Center auto-syncs (publish/unpublish flows through), and other sources can be resynced when they change.
Will the agent make things up? A well-built one answers from your knowledge and escalates when the answer isn't there. Grounding plus a clear escalation path is what keeps it honest.
Does connecting a big knowledge base cost a lot? No — indexing and embeddings aren't charged against credits. You only pay for the agent's responses.
The bottom line
Connecting your knowledge base is the highest-leverage thing you can do to make an AI agent trustworthy. Bring in your help center and your internal docs, curate what you connect, keep it current, and scope each agent to the right sources. Do that, and your agent stops guessing and starts answering from your truth.
Ground an agent in your own knowledge: connect your help center and docs, and build an agent that answers from them — 7-day free trial, no credit card required. Start a free trial.
Resolve tickets automatically with AI agents
Macha's AI agents work on top of the help desk you already use — no code.














