



 Shopify
Shopify Stripe
Stripe Slack
Slack Notion
Notion Google Workspace
Google Workspace Confluence
ConfluenceHow to Turn Your Past Zendesk Tickets into an AI Knowledge Base (with Studies)


Your best support knowledge usually isn't in your help center. It's buried in a year of resolved tickets — the real questions customers asked and the real answers your team gave. The trouble is that knowledge is locked inside thousands of individual tickets that nobody will ever re-read.

Macha's Studies feature unlocks it. You point AI at your past Zendesk tickets, tell it exactly what to pull out of each one, and turn the result into a searchable knowledge base your AI agents can use — so the next customer with the same question gets answered from how you actually solved it last time. No CSV exports, no scripts, no data leaving your stack.
This guide walks through the whole thing, screen by screen.
Why your past tickets are a goldmine
Every resolved ticket is a tiny piece of documentation: a real question, the context around it, and a working answer. Across a year, that's an enormous, battle-tested FAQ — and it covers the messy edge cases your help center never will, in the exact words your customers use.
The catch has always been scale. You can't read 20,000 tickets. You can't hand-write help articles for all of them. And the moment a great answer is given, it sinks to the bottom of the queue and is gone. The knowledge exists; it's just unusable in that form.
That's precisely the kind of work AI is good at — reading a huge pile of text and pulling out the useful parts — if you have a way to run it across every ticket at once.
The old way vs. the Macha way
You could do this by hand. Export your tickets to CSV, write a script that calls an LLM over each row, parse and clean the output, then figure out where to store it so something can actually use it. If you're technical and patient, it works — we've seen teams do exactly this in a coding environment, downloading tickets and running AI on them offline.
Macha does it on the platform, over your live Zendesk data, with no exporting and no code. You connect Zendesk once, describe what you want extracted, and Studies runs the analysis and drops the results straight into a knowledge source your agents can search. The data and the AI live in the same place — that's the whole point.
What Studies is, in one line
Studies runs an AI model over a set of records — like your Zendesk tickets — and fills a structure you define, producing one row of results per record. You can then analyze those results or push them into your agents' knowledge.
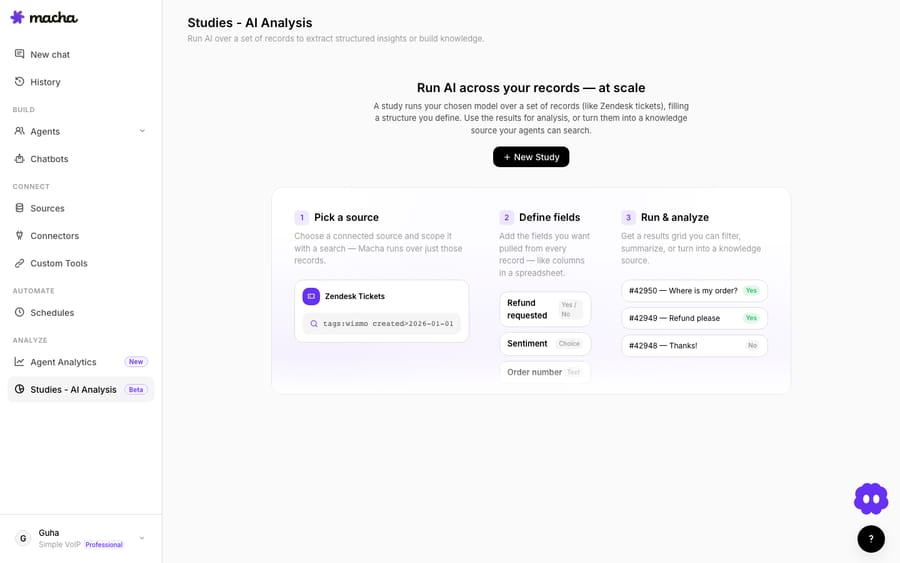
The flow is a four-step wizard — Source → Scope → Extract → Review — and then a push to knowledge at the end. Let's go through each.
Step 1 — Source: what are you studying?
Start a New Study and pick the source Macha should run over. Choose Zendesk Tickets (you'll need Zendesk connected first, under Connectors). Macha runs your analysis across that source's records — one row of output per ticket.
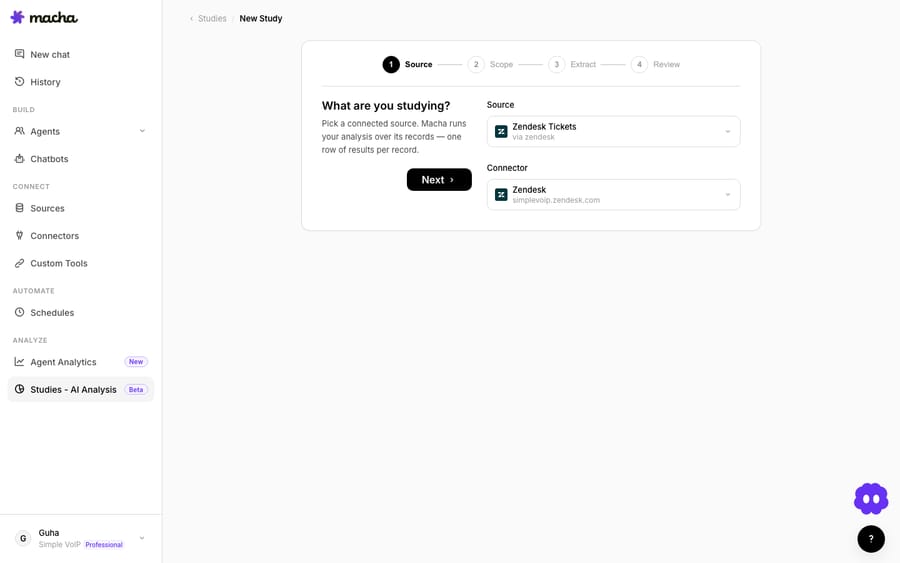
This is also where the mental model clicks: a Study isn't a chat or a single prompt — it's a batch job that treats every ticket as a row and fills in the columns you define.
Step 2 — Scope: which tickets, and what the AI reads
This step does two important jobs: it decides which tickets get processed (which also controls your cost), and what the AI is allowed to read from each one.
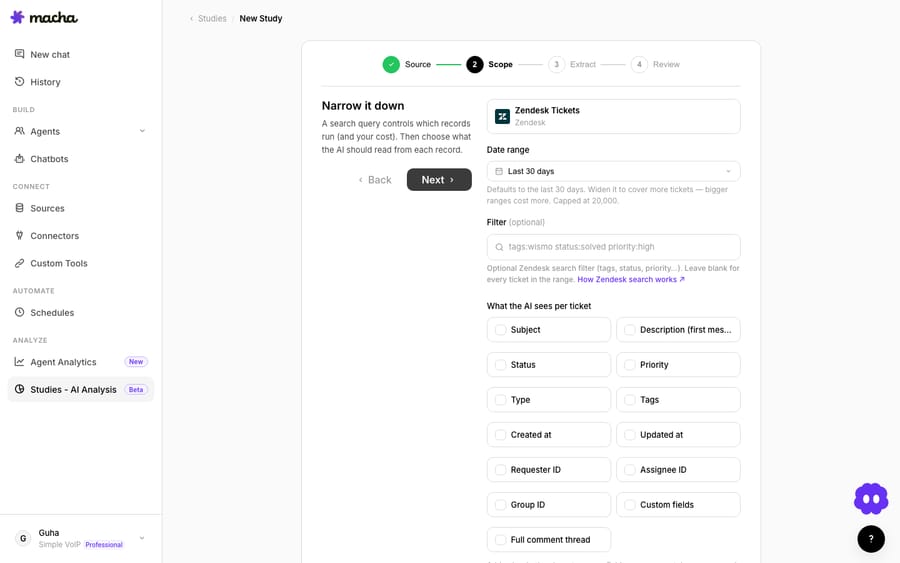
Date range. Defaults to the last 30 days. Widen it to cover more history — but remember bigger ranges mean more tickets and more cost, and a single run is capped at 20,000 tickets. For a knowledge base, a 6–12 month window of resolved tickets is a sweet spot.
Filter (optional). A Zendesk search query that narrows the set further — for example tags:wismo status:solved priority:high. Leave it blank to include every ticket in the range. This is the single most useful lever for both quality and cost: scoping to status:solved (tickets that actually have answers) and one topic at a time gives you a clean, cheap first run.
What the AI sees per ticket. This is the part most people miss. You tick exactly which fields the AI reads for each ticket — Subject, Description (first message), Status, Priority, Type, Tags, Created/Updated dates, Requester/Assignee/Group IDs, Custom fields, and the Full comment thread. Fewer fields means cheaper and more focused; the full comment thread gives the AI the entire back-and-forth (the richest context, but more tokens). For building a knowledge base, Subject + Full comment thread is usually the right combination — that's where the actual resolution lives.
Step 3 — Extract: define what to pull out
This is the heart of a Study. You define a schema — the columns you want filled for every ticket, like a spreadsheet — plus the model and any guidance.
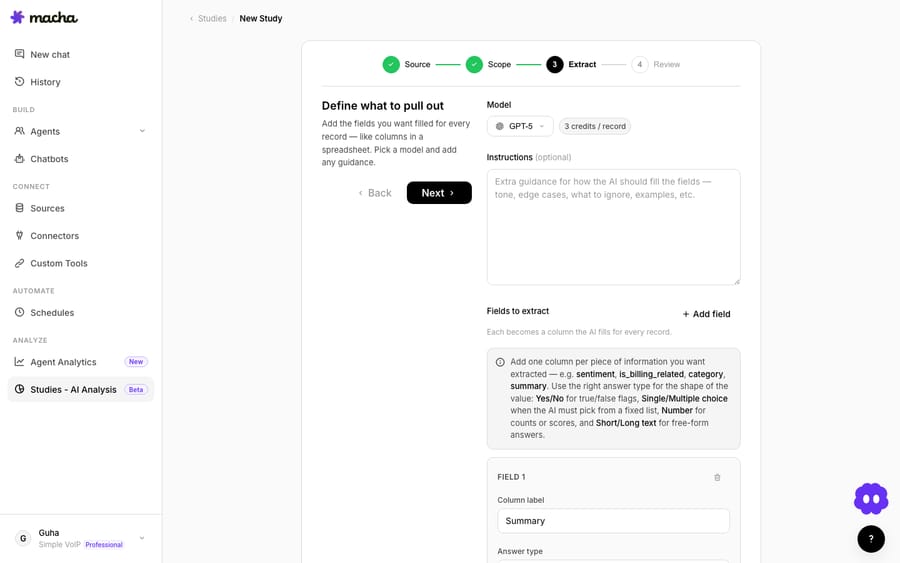
Model. Each model shows its per-record credit cost. Extraction is straightforward work, so a fast, low-cost model (like GPT-5.4 Mini) is usually all you need — and across thousands of tickets, the model choice is the biggest driver of cost.
Instructions (optional). Free-form guidance on how the AI should fill the fields — tone, edge cases, what to ignore, examples. For a knowledge base, something like: "Write each answer as a clear, self-contained solution a new customer could follow without seeing the original ticket. Ignore internal-only chatter."
Fields to extract. Add one column per piece of information you want, each with a Column label and an Answer type:
- Yes/No — true/false flags (
refund_requested,bug_report). - Single / Multiple choice — when the AI must pick from a fixed list (
category,product_area). - Number — counts or scores.
- Short / Long text — free-form answers (
question,answer,summary).
For turning tickets into a knowledge base, a good starting schema is:
| Column | Type | What it captures |
|---|---|---|
question | Short text | What the customer was actually asking |
answer | Long text | The resolution, written as a reusable answer |
category | Single choice | Billing · Shipping · Technical · Account… |
product_area | Single choice | So agents can scope to the right area |
That's it — those four columns turn a raw ticket into a clean Q&A entry.
Step 4 — Review: estimate and run
The Review step summarizes everything — source, account, scope dates, fields, and model — and lets you estimate the cost before you run. Running a study saves it automatically.
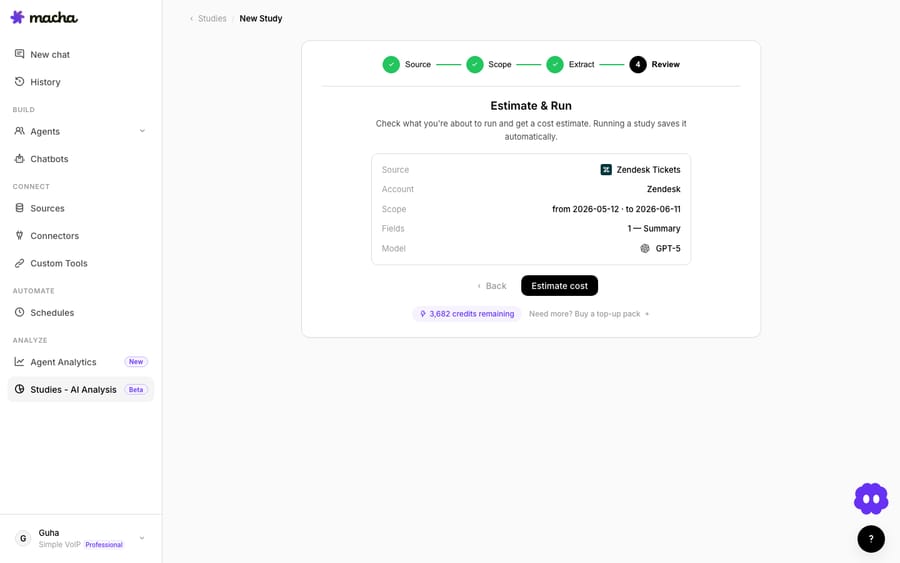
Two safety nets matter here:
- Test run first. Run on a small sample to see how well the AI fills your schema before committing. If the answers aren't clean, go back to Step 3, tweak the instructions or fields, and test again. Iterate on a handful of tickets — not on 10,000.
- Cost estimate gate. Macha shows the projected credits for the full run, and credits are deducted incrementally per record as it runs (with live progress) — so a big run never silently blows your balance. Each run is also an immutable snapshot, so you keep a full history.
Step 5 — Push the results into a Knowledge Source
When the run finishes, push it into a Knowledge Source. Every row becomes a searchable document, indexed like any other knowledge. Now link that source to an agent and it can answer from your real, historical resolutions — right alongside your help center.
This is the payoff: a year of resolved tickets becomes a living FAQ your agents search. The next "how do I change my billing date?" gets answered from the dozen times your team already answered it. (See how to connect a knowledge base to an AI agent for the linking step.)
It's not just for knowledge bases
The same wizard extracts anything you can describe — change the schema and you get instant analysis of a year of support data:
- Sentiment & CSAT drivers — add a
sentimentandfrustration_reasoncolumn and see what's actually making customers unhappy. - True contact-reason breakdown — a
categorycolumn reveals why people really write in, which is often very different from your existing tags. - Risk and revenue signals — flag
refund_requested,bug_report,cancellation_risk, orupsell_opportunityacross every ticket. - Knowledge gaps — a column for "was this answerable from existing docs?" tells you exactly what to write next.
It's the fastest way for an admin to run AI over a year of tickets and actually learn something — no BI project required.
Plans and cost
Studies is available on the Professional plan and up ($699/mo). Runs are billed in credits, deducted per record, the per-record cost depends on the model you choose, and you always see an estimate from the test run before the full run commits. 7-day free trial, no credit card required.
Best practices
- Start narrow. One topic or product area,
status:solved, a few months. Get the schema right, then widen. - Pick the cheapest model that fills the schema well. Across thousands of records this is your main cost lever.
- Iterate with the test run. Never run the full set until a sample looks clean.
- Choose fields deliberately. "Full comment thread" gives the richest context for answers; trim fields you don't need to save tokens.
- Refresh quarterly. Re-run on recent tickets so the knowledge stays current — each run is a snapshot, so you never lose history.
Frequently asked questions
What is Macha Studies? A feature that runs an AI model over a set of records (like Zendesk tickets) and extracts a structured result for each — which you can analyze or push into your agents' knowledge base.
Do I need to export tickets or write code? No. Studies runs on the platform over your connected Zendesk data — no CSV exports, no scripts.
How much does a run cost? It uses credits, deducted per record; the per-record cost depends on the model. You approve a cost estimate from a small test run before the full run. Studies is on the Professional plan and up.
How many tickets can I analyze at once? Up to 20,000 records per run, processed with bounded concurrency and live progress.
What should the AI read from each ticket? Pick fields in Step 2. For a knowledge base, Subject + the Full comment thread captures the question and the resolution; trim the rest to save cost.
Can my agents actually use the results? Yes — push a completed run into a Knowledge Source and any linked agent can search it, exactly like your help center.
The bottom line
The answers your team has already given are your most valuable — and most wasted — knowledge. Studies turns a year of resolved Zendesk tickets into a searchable knowledge base (and a goldmine of analysis) in four steps, right where your data already lives. Connect Zendesk, scope the tickets, define what to extract, review the cost, run, and push it to your agents.
Put your past tickets to work: run your first Study and turn resolved tickets into agent-ready knowledge. 7-day free trial, no credit card required. Start free.
Add AI agents to your Zendesk
Macha resolves tickets end to end, right on top of Zendesk — no migration.














