



 Shopify
Shopify Stripe
Stripe Slack
Slack Notion
Notion Google Workspace
Google Workspace Confluence
ConfluenceWhat Is Macha Studies? Run AI Over Your Tickets at Scale


Most AI features in a support tool work one ticket at a time — answer this one, summarize that one. Studies works the other way: it runs an AI model across a whole pile of records at once and pulls out structured data from each. Point it at a year of Zendesk tickets and, in one run, you get a clean table of what every ticket was about, how it was resolved, the sentiment, the category — whatever you tell it to extract.

It's the difference between asking AI a question and putting AI to work on your entire dataset.
The one-line definition
Studies runs your chosen AI model over a set of records — like your Zendesk tickets — and fills a structure you define, producing one row of results per record. Think of it as turning thousands of messy tickets into a tidy spreadsheet where every column is something an AI read and decided.
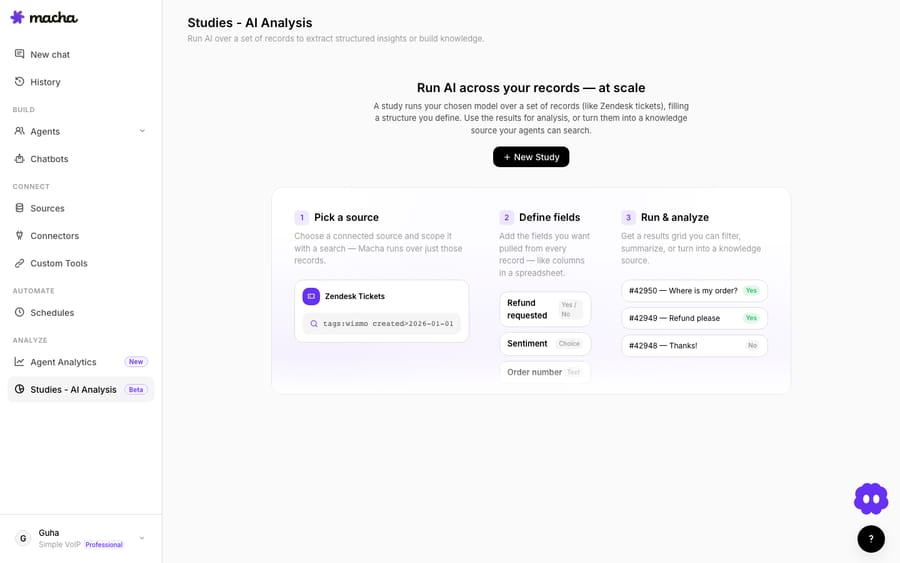
How it works (the four steps)
Every Study is a quick four-step wizard:
- Source — pick what to run over (today, Zendesk Tickets).
- Scope — choose which records (a date range and an optional search filter) and what the AI reads from each one.
- Extract — define the columns you want filled, pick a model, and add any guidance. This is the heart of it: each column is a piece of information you want pulled from every record.
- Review — see a cost estimate and run.
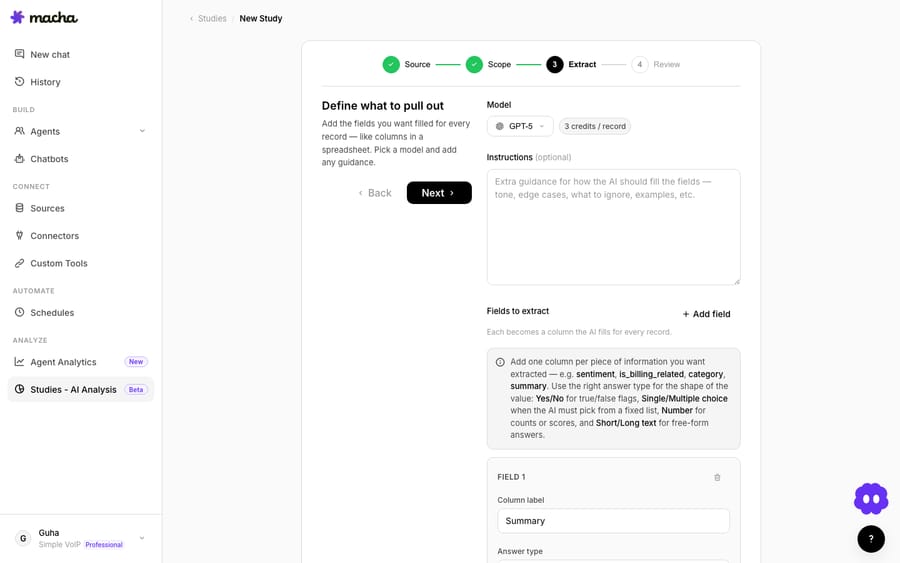
The columns can be any shape: Yes/No flags, single/multiple choice from a fixed list, numbers, or short/long text. That flexibility is why the same feature can build a knowledge base, run sentiment analysis, or tag a backlog — you're just changing what the columns are.
What you can actually do with it
Because you define the output, Studies is really a general-purpose "run AI over my data" engine. The common jobs:
- Turn past tickets into a knowledge base — extract the question and the resolution from each ticket, then push the results into a knowledge source your agents search. (Full how-to.)
- Analyze a year of support — sentiment, true contact reasons, refund/bug/churn signals, trends. (Full how-to.)
- Tag or categorize a backlog — apply consistent categories across thousands of old tickets that were never tagged.
- Find knowledge gaps — flag which questions your help center couldn't answer, so you know what to write.
- QA and compliance — score tickets against criteria you define.
If you can describe what you want pulled out of each ticket, Studies can extract it.
Why it's safe to run on a lot of data
Two design choices keep a big run from being scary:
- Test run first. Run on a small sample, check the quality, and only then commit to the full set. You iterate on a handful of tickets, not ten thousand.
- Cost estimate + incremental billing. Before the full run, you see an estimate; during it, credits are deducted per record with live progress, and you can cancel mid-run. There's no way to accidentally burn your whole balance.
Every run is also an immutable snapshot — re-running creates a new one, so you keep a full history for comparison and audit. And the hard cap is 20,000 records per run.
Example schemas (it all comes down to the columns)
The whole feature is really just "what columns do you want?" Three quick examples:
Knowledge base — turn tickets into reusable answers: question (short text) · answer (long text) · category (single choice) · product_area (single choice)
Sentiment & insight — understand a year of support: sentiment (single choice: positive / neutral / negative) · contact_reason (single choice) · frustration_driver (short text) · was_resolved (yes/no)
Backlog cleanup — tag old tickets consistently: topic (single choice) · priority (single choice) · is_billing_related (yes/no) · summary (short text)
Same engine, different columns — that's the whole idea.
Who it's for
Studies is an admin power feature. It's for the person who wants to understand or operationalize a year of support data — turn it into agent knowledge, surface what customers actually struggle with, or clean up a tagging mess — without exporting CSVs or writing scripts. The data and the AI are already in the same place; Studies just lets you point one at the other.
Plans and cost
Studies is available on the Professional plan and up ($699/mo). Runs are billed in credits per record, the rate depends on the model you choose, and you always approve an estimate before the full run. 7-day free trial, no credit card required.
Frequently asked questions
What is Macha Studies in one sentence? A feature that runs an AI model over a set of records (like Zendesk tickets) and extracts a structured result for each — one row per record.
What can I extract? Anything you can describe as a column: yes/no flags, categories, numbers, or free text (a summary, a resolution, a question).
Is it just for tickets? Today the input source is Zendesk Tickets, with more sources on the roadmap.
How is this different from chatting with an agent? Chatting handles one request at a time. Studies runs a model across your whole dataset at once and returns structured results.
Can the results feed my agents? Yes — push a completed run into a Knowledge Source and any linked agent can search it.
The bottom line
Studies turns "I wish I knew what's in all those tickets" into a few-minute job. Define the columns you want, scope the records, review the cost, and run — and a year of support data becomes a structured table you can analyze or feed straight back to your agents.
See what's in your tickets: run your first Study in minutes. 7-day free trial, no credit card required. Start free.
Resolve tickets automatically with AI agents
Macha's AI agents work on top of the help desk you already use — no code.














